kamuszhou的博客,转载请注明URL。
现代大规模集成电路图(VLSI)非常庞大,当我们希望用多个FPGA仿真一个VLSI时,需要把VLSI在满足一些约束条件的情况下切割成多个小部分,每个部分都可以装进一个FPGA。
这个问题抽象成数学模型,实际上就是一个超图分割的问题。在超图分割领域有一篇发表于1982年的论文,名字是”A Linear-Time Heuristic for Improving Network Partitions”。这篇论文提出了一种改进的“超图二分问题”算法,简称为FM算法。虽然在1982年这篇论文发表时,“超图分割”算法领域已经发展了近十年。但这篇论文似乎有着近乎祖师爷级论文的地位,相当多的后期该领域的论文都会引用这篇文章。论文发表之后该领域继续发展出的“层次化超图多分割”算法可以看成是FM算法发展而来。该算法中涉及到的概念和思路是后续算法的基础,是很好的该领域入门学习的资料。
(更多超图及超图分割的基础概念请自行搜索,本博客主要解读论文)
论文的下载地址:
https://ieeexplore.ieee.org/document/1585498
在论文的摘要部分论述到:本文提出了一种启发式的,利用最小割(mincut)的迭代算法解决超图二分问题。该算法在最坏情况下的时间复杂度也是线性的。在实际应用中,绝大多数情况下,该算法都只需要很少次数的迭代。算法有三个特点:
1. 超图被分成两个Block。每次移动一个结点把它从原来的Block移往另一个Block。同时维持两个Block的平衡。重要的是,这个平衡不是基于每个Block中的结点数量,而是更一般的size of block的概念,它考虑到了每个结点的权重是不一样的。
2. 利用一个相当高效的数据结构,可以在O(1)常数时间复杂度内找到需要移动的最佳结点。
3. 在移动了某个结点后,再高效地更新受上次移动影响的结点的信息(即论文后面会提到的结点的gain值)。这第三个特点亦在论文的Introduction中被再次提到,作者认为这是该论文的主要贡献(main contribution).
术语及基本概念
- n(i): 当i是超边的编号时,n(i)定义为每个超边上的结点数目。
- s(i)或p(i): 当i表示结点时,s(i)或p(i)表示结点上的PIN数目,即结点一共跟多个条超边有连接,更多时候亦称为结点的size。
- 邻居结点: 如果两个结点至少能通过一条超边连接,即为邻居结点。
- A,B: 代表超图二分割后的两个BLOCK。
- |A|: |A| = \sum_{i=i}^{n}{s(i)} 即Block A的size定义为Block A中所有的结点的size的连加。
- A(n)或B(n): n表示编号为n的边,A(n)则表示该条n在Block A中的结点数。
- cut: 在A和B中都有结点的超边。
- cutstate: 一条超边是不是cut(后来发展成多分割问题中的cutsize)。
- cell gains: 当移动一个结点到另一个BLOCK时,cut减少的数目。
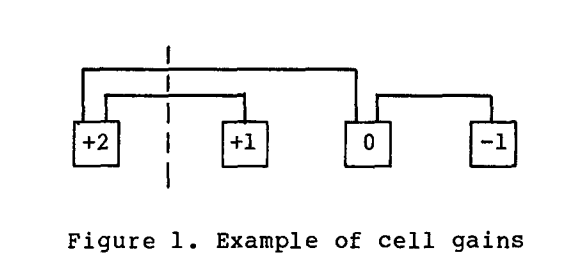
维持平衡
最容易想到的是就是使超图二分割后的两个BLOCK中的结点数量大致相同。不过,可以稍微变复杂一点,即考虑每个结点的权重。
* W = |A| + |B| 所有结点的size连加和
* r = |A| / (|A| + |B|) 一个大小0到1之间的比率
* smax = \max_{1<i<n}{s(i)} 最大的结点size
* rW – k * smax <= |A| <= rW + k * smax;k > 1 平衡公式
公式不难,描述地很清楚。简单地讲,block的size考虑到了每个结点的权重不同。另外,允许每个block的size在满足比率r的附近上下浮动k个最大结点size。它的含义是,在刚好满足分割比率r的时候,还能够至少移动k个结点。
算法描述
- 随机找到一个划分A, B (初始划分并未严格要求是在平衡状态)
- 从A和B中都找出它们各自拥有最高gain值的结点,即有两个预备结点。
- 淘汰掉移动后会导致不平衡状态出现的预备结点。如果两个预备结点均被淘汰,则算法结束。
- 在这两个结点中选择拥有最高gain值的结点移动到对端。如果这两个预备结点gain值一样,就选会导致更好平衡状态的结点。如果还是一样,那就随你的心情挑一个(break ties as desired)。
- 锁定该结点,在本次迭代中不准再使用。
- 更新各个结点的gain值,跳到步骤2继续下一次迭代。
高效的数据结构
FM算法中有两个难点,即如何快速找到每个Block中gain值最高的结点以及高效的更新gain值以反应移动结点带来的变化。第一问题由下图所示的数据结构解决。
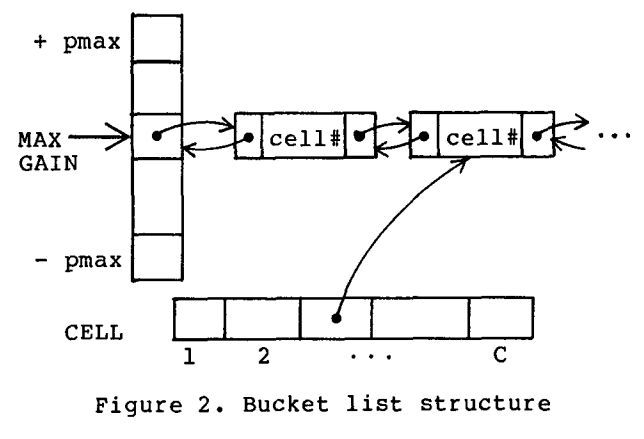
如图的数据结构共有两个。A,B两个BLOCK各有一个。其中 pmax即所有结点中最大size。显然,每个结点的gain值都在[-pmax, +pmax]之间。当pmax值相对较小时,可以用一个静态数组表示。FM论文中即用静态数组,但后来VLSI持续发展,静态数组太大的时候,即可换成用hash表。图中,坚着的数组表示在每一个gain值下面用链表存放Free结点,并用一个标记记录当前最高gain值是多少。横着的数组则存放了所有的结点。这样,就能在常数时间内找到最大的gain值和任意一个结点。
高效地更新gain值
当一个结点从当前BLOCK移到对端BLOCK后,会造成它的所有邻居结点的gain值有可能发生变化。如果用一个naive的算法,效率会很低。论文中论述了naive方法的时间复杂度O(P^2),P表示超图中所有PIN的总数目。这个时间复杂度很吓人,但我认为这是最坏极端情况下。但更详细的论述这里就略过吧,主要讲FM算法是怎么做的,这是该论文作者最得意的部分。
先引入关键边的概念。
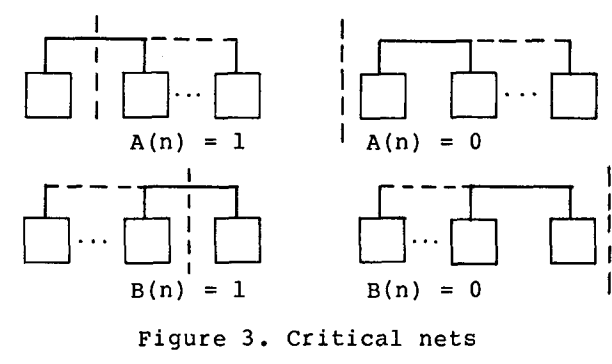
当且仅当A(n)或B(n)等于0或者等于1时,一条边能称之为关键边。
(kamuszhou的博客,转载请注明源URL)
两个重要论述:
-
If the net is not critical, its cutstate cannot be affected by a move
如果一条边不是关键边,那么不可能只通过一次移动改变该边的cutstate。
-
A net which is not critical either before or after a move cannot possibly influence the gains of any of its cells.
如果一条边在移动前和移动后,它都不是关键边,那这条边则不影响gain值的更新。
那不就是~~~~
如何更新gain值,只用管移动前是关键边,或者移动后是关键边这两种情况么!!!
考察一个结点,把该结点从From Block移动到To Block这个移动前后的状态。
F(n)定义为一条超边n在From Block中的结点数。
T(n)定义为一条超边n在To Block中的结点数。
移动前符合哪些条件的边是超边呢?
F(n) = 1 or T(n) = 0 or T(n) = 1 其中F(n) = 0违反条件,不存在。
移动后哪些边是超边呢?
T(n) = 1 or F(n) = 0 or F(n) = 1 其中T(n) = 0违反条件,不存在。
再度惊人地发现!!!
移动前的F(n) = 1 即是移动后的 F(n) = 0
移动前的T(n) = 0 即是移动后的 T(n) = 1
于是~~符合什么条件的超边将影响gain值简化为:
移动前符合:
T(n) = 0 or T(n) = 1
移动后符合:
F(n) = 0 or F(n) = 1
于是,得到算法:

本文未尽细节
本文省略了如何计算每个结点的初始gain值,和如何生成初始状态的数据结构。因为这两个算法都相对简单,所以就略过,着重于论文作者最为得意的高效更新gain值的部分。
Our main contribution consists of an analysis of the effects a cell move has on its neighboring cells and a subsequent efficient implementaion of these results.
本文还省略了论者发现的几个命题(proposition),及一些算法复杂度的分析和证明。
还省略了其他细节~最好还是读原文!给你不一样的丝滑感受。
FM算法的缺点
在另一篇论文中,提到FM算法的3个缺点。
1. 当两边Block选出的gain值一样时,给的处理方式过于简单,不够有洞察力(insightful)。
2. 当一条超边在两个Block中的结点数都大于或等于两个时,它们就没有资格在第一时间被选为待移动结点。这显然太过greedy了。
3. 好像还提到过其他缺点但是我忘记了~
读后感
为何大佬那么厉害~
一个结点的移动对它的邻居结点gain值的影响的分析确实相当之精彩。虽然没有复杂的数学公式,但同样逻辑严谨,抽丝剥茧的分析。让人拍案叫绝~
为何作者能思考得这么有条理和深入??
除了具体的算法本身,还能学到哪些思考分析复杂问题的方式呢?
1. 简化问题
2. 提炼规律
转载请注明出处。